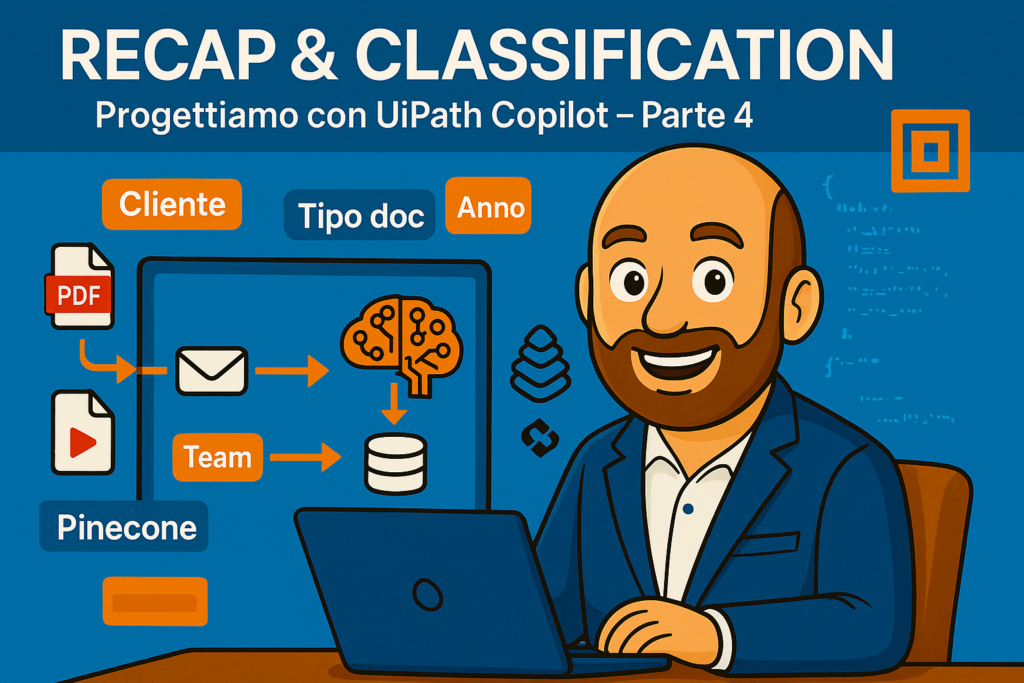
Nel terzo articolo della serie dedicata alla progettazione di un sistema RAG locale per studi legali, ci si concentra sull’importanza della preparazione e classificazione dei dati prima dell’embedding. Dopo le difficoltà incontrate con l’integrazione LangChain in UiPath, il team ha sviluppato un proprio container Docker per gestire e normalizzare i file, in particolare per distinguere tra contenuti pubblici e documenti legali riservati.
Il cuore del sistema è la categorizzazione interna dei documenti, un passaggio fondamentale per evitare problematiche legate alla sicurezza e per ridurre il rischio di “allucinazioni” durante l’interrogazione del modello. Si evita infatti l’uso di strumenti esterni per la classificazione automatica, optando per un approccio locale più sicuro.
Il motore di embedding scelto è Pinecone, preferito a OpenAI per motivi di costo, sicurezza dei dati (con server europei) e portabilità. I chunk di dati vengono caricati con una categorizzazione preinserita, garantendo coerenza semantica nella fase di ricerca e interrogazione.
Nel prossimo articolo verrà sviluppato un modello LLM locale addestrato per riconoscere e classificare cinque diverse tipologie documentali dello studio legale, gettando le basi per la costruzione di una chat legale friendly basata su architettura RAG personalizzata.