
1. Riepilogo e considerazioni

In questo paragrafo ripercorriamo brevemente i temi trattati nei tre articoli precedenti, evidenziando alcuni punti che vale la pena chiarire. In passato ho lavorato principalmente con UiPath e i suoi strumenti di intelligenza artificiale, che gestiscono in modo integrato l’ispezione, la categorizzazione e il controllo dei dati attraverso interfacce grafiche e flussi preconfigurati.
Sviluppare ogni singolo passaggio manualmente, come stiamo facendo qui, offre un maggiore grado di personalizzazione, ma comporta anche la necessità di risolvere manualmente molte complessità.
Più avanti, dedicheremo un capitolo per valutare i vantaggi e gli svantaggi di affidarsi all’ecosistema UiPath rispetto a una soluzione basata sui singoli tool.
Approfondire questi meccanismi è comunque un ottimo esercizio formativo, perché aiuta a comprendere meglio i motivi e le logiche alla base delle scelte progettuali. Ora torniamo al nostro progetto.

Negli articoli precedenti abbiamo innanzitutto centralizzato l’acquisizione delle informazioni, caricando documenti provenienti da fonti diverse (e-mail, siti web, video di YouTube, ecc.) in un unico sistema. Questa scelta ci ha permesso di ridurre la dispersione dei dati e di disporre di un punto di riferimento unico per tutte le analisi successive. Dire unico non significa solo uno per tutti.
Ogni avvocato ha la possibilità, collegando il suo computer al cloud Uipath, di scaricare, se già non ce là, l’ultima versione del programma di caricamento dei documenti nel database utilizzato dall’intelligenza artificiale.
Parallelamente, è stata presa la decisione di utilizzare Docker in combinazione con LangChain, per garantire un ambiente di lavoro più solido e standardizzato. Docker, infatti, semplifica la configurazione, isola le dipendenze e rende la distribuzione del servizio molto più agevole, anche in contesti professionali complessi. Inoltre, per preservare la riservatezza dei dati, abbiamo stabilito che i servizi di segmentazione (chunking) dovessero rimanere all’interno del perimetro aziendale, esponendo il servizio tramite l’indirizzo IP e la porta 5000 del PC su cui Docker è in esecuzione (o al servizio in cloud se fuori sede).
Questa architettura è stata definita dal nostro Solution Architect, che ha valutato attentamente la necessità di caricare i documenti anche da postazioni remote, di implementare un sistema di controllo accessi e di poter distribuire facilmente la soluzione su più PC. A seguire, l’integrazione di UiPath Orchestrator ha rappresentato un passo cruciale: da una parte, ha elevato il livello di sicurezza e affidabilità, dall’altra ha reso i flussi di inserimento e gestione dei documenti più tracciabili e in linea con gli standard aziendali.
Naturalmente, inserire LangChain in un container Docker ha introdotto anche nuove complessità, soprattutto sul versante della gestione delle chiamate. Tuttavia, l’approccio a microservizi ha permesso di pubblicare endpoint HTTP attraverso uno script Python che importa LangChain e ne espone le funzioni principali, offrendo flessibilità nella personalizzazione e facilità di integrazione.

Questi passaggi, in definitiva, hanno gettato le basi per il lavoro che svilupperemo: da un lato, assicurano che la gestione dei dati avvenga in modo sicuro e totalmente interno all’organizzazione; dall’altro, forniscono un ambiente flessibile in cui continuare ad ampliare le funzionalità legate all’analisi documentale e all’utilizzo di LLM. Nella prossima sezione vedremo più nel dettaglio come sono evolute le procedure di inserimento dei documenti.
2. Classificazioni (Attività concettuale)
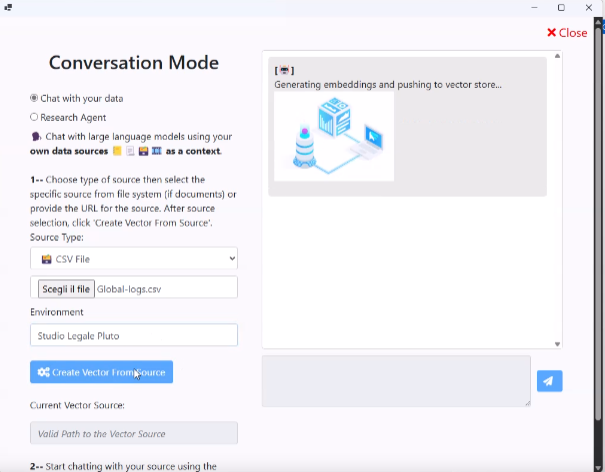
La classificazione dei dati è un passaggio cruciale per sfruttare appieno le potenzialità di un database vettoriale come Pinecone. Questa piattaforma, oltre a gestire gli embedding, consente di associare metadati (o categorie) ai vettori, migliorando notevolmente la ricerca e il retrieval delle informazioni.
Un sistema di classificazione ben strutturato offre notevoli vantaggi. Per esempio, l’adozione di chiavi di classificazione legate a codici fiscali o gruppi di lavoro permette di controllare rigorosamente chi ha accesso a determinati documenti, bloccando eventuali consultazioni non autorizzate. Allo stesso modo, altre chiavi come la tipologia del documento o la materia legale aiutano il modello a restituire risultati più pertinenti nelle ricerche semantiche o nelle attività di Q&A.
Di seguito, sono elencate cinque dimensioni di classificazione adottate per gestire con efficacia i dati nei vettori:
- Gruppo Codice pratica del cliente (clienti)
Identifica in modo univoco il cliente/i coinvolto/i. dalla pratica si determina il codice fiscale, i cellulari, le email autorizzate ad accedere via whatsapp, email etc ai documenti .- Esempio: {“Gruppo aa1″:”RSSMRA80A01H501U”,”Gruppo aa1″:”SCLOTT99H30G273Y”} -> nel db vettoriale inseriremo “Gruppo aa1”
- Questa chiave facilita l’isolamento delle informazioni relative a uno specifico cliente-gruppo di clienti cointeressati, rendendo più semplice la protezione dei dati sensibili.
- Gruppo di lavoro degli avvocati (avvocati)
Serve per la gestione interna, l’assegnazione dei documenti e il filtro degli accessi.- Esempio: {“CIVIL A”:”Avvocato xxx”,”CIVIL A”:”Avvocato yyy”} -> nel db vettoriale inseriremo “CIVIL A”
- Una categoria statica (come il codice del gruppo) mantiene stabile la classificazione nel database. L’elenco delle persone autorizzate varia invece, come nell’esempio precedente, in una tabella esterna, senza che sia necessario modificare direttamente i dati indicizzati. In questo modo, si garantisce la separazione tra contenuto (memorizzato nel database vettoriale) e autorizzazioni (gestite esternamente), favorendo la tracciabilità e la scalabilità.
- Tipo di documento (tipo_documento)
Descrive il formato o la funzione del documento.- Esempi: contratto, procura, atto, fattura, email, whatsapp.
- È particolarmente utile per query che puntano a documenti specifici, come “Mostra tutti gli atti per questo cliente”.
- Materia legale (materia)
Specifica il contesto giuridico del documento.- Esempi: civile, penale, lavoro, famiglia, societario, tributario.
- Fondamentale per domande quali: “Filtra i documenti di diritto societario”.
- Anno di riferimento / Periodo (anno)
Inquadra il contesto temporale del documento.- Esempi: 2023, 2024, 2025.
- Consente ricerche puntuali su una fascia temporale, ad esempio: “Trova le procure di Mario Rossi del 2022”.
Piccola precisazione. Il database llm personalizzato che stiamo alimentando con le informazioni estratte dai documenti, dalle email, dall’organigramma, dal sito aziendale, dal libro delle procedure da youtube ecc. non serve solo per fornire i documenti” on demand” ma anche per creare servizi di centralino, customer service personalizzati ed efficienti.

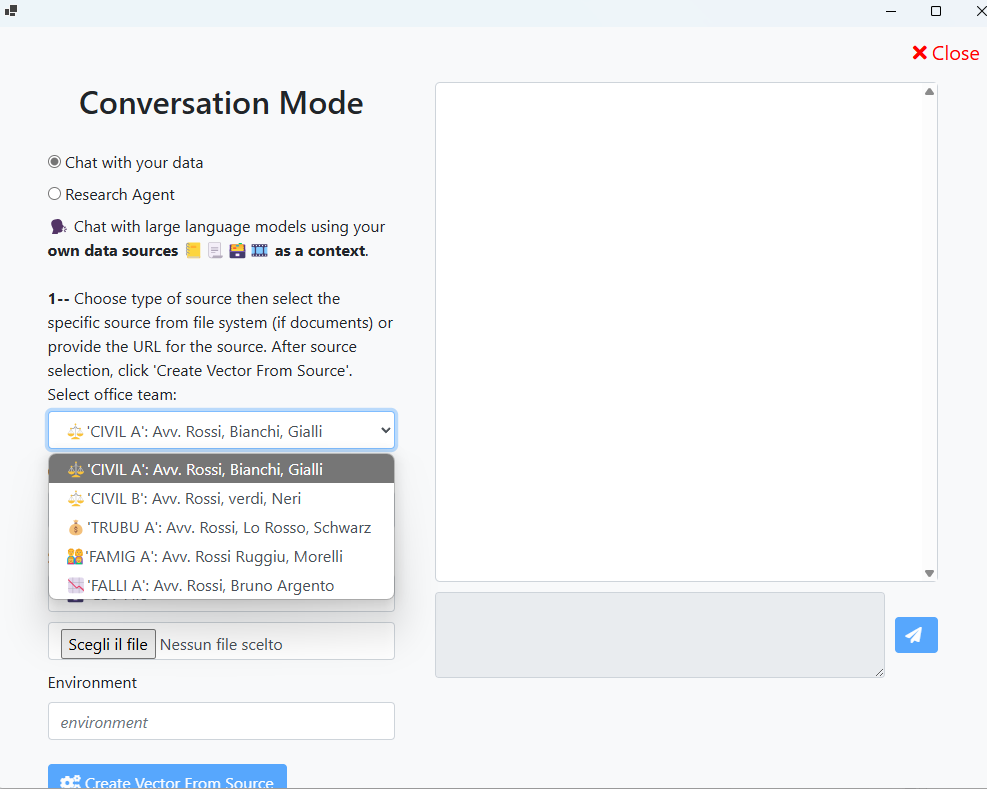
Il form di caricamento dei documenti viene arricchito con il campo del gruppo di lavoro o delle persone dello studio che possono accedere alle informazioni in esse contenute
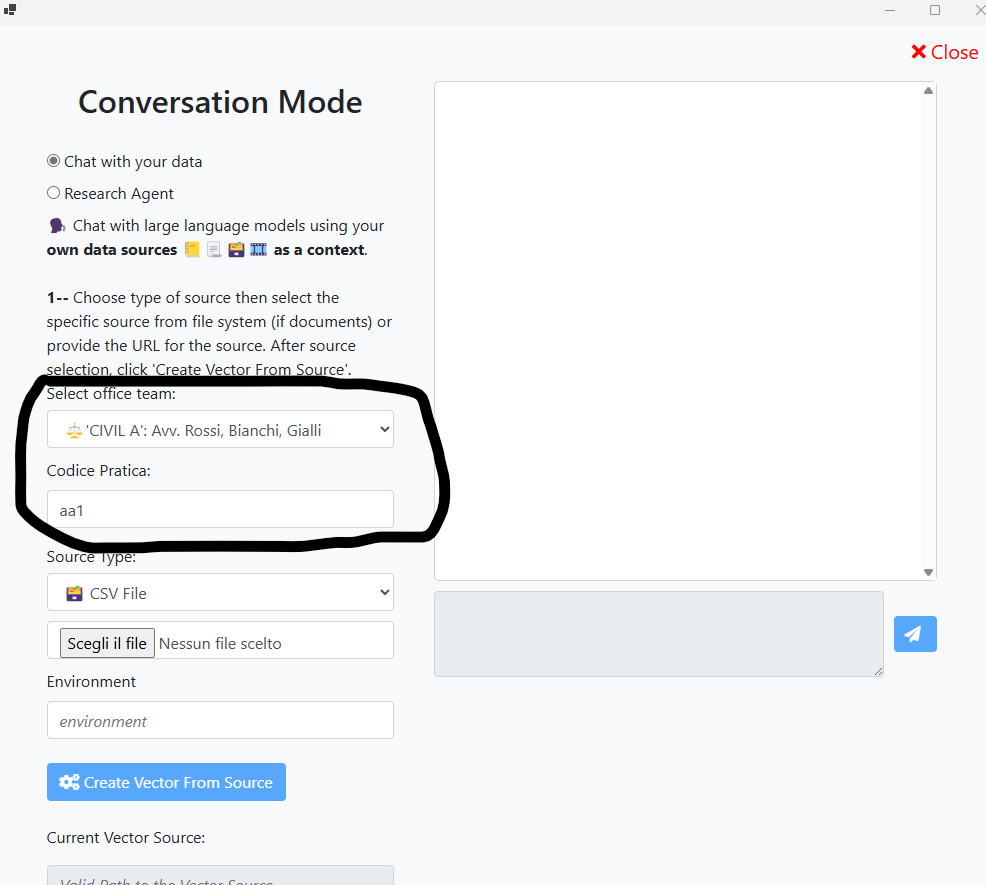
Il form di caricamento dei documenti viene arricchito con il campo del codice pratica per aggiungere altri permessi di accesso alle informazioni lato cliente
Si può snellire il flusso di inserimento, facendo in modo che l’avvocato non debba inserire manualmente tutte le informazioni: il form di caricamento può essere modificato con funzioni di ricerca sul database aziendale, così facendo il medesimo avvocato selezionerebbe una tantum un elenco di opzioni valide, minimizzando i rischi di errore e velocizzando l’intero processo di caricamento nel database LLM delle informazioni aziendali. Di conseguenza, l’estrazione e la classificazione dei documenti risulteranno più affidabili, poiché ogni documento verrà caricato con metadati certi e conformi alle tabelle ufficiali dello studio.
Inoltre, l’ottimizzazione di questa fase di upload si traduce in una gestione più fluida a livello di orchestrazione, riducendo i tempi di elaborazione e prevenendo incongruenze di dati tra i diversi sistemi. Grazie all’integrazione diretta con il database aziendale, ogni nuovo documento caricato dispone immediatamente della corretta categorizzazione, favorendo una migliore analisi e un più rapido recupero delle informazioni nelle fasi successive.
Fatta questa precisazione teorica sulle dimensioni che riteniamo utili implementare, possiamo finalmente dedicarci alla realizzazione del nostro sistema LLM in situ e divertirci ad implementarlo e interrogarlo.
Nel prossimo capitolo faremo le interrogazioni sui documenti. faremo il prompt engineering per rendere efficiente le interrogazioni necessarie ad alimentare il nostro sistema di classificazione. chiuderemo la fase di caricamento dei dati privati del nostro studio legale.

3.Code di orchestrator e pareparazione dei batch
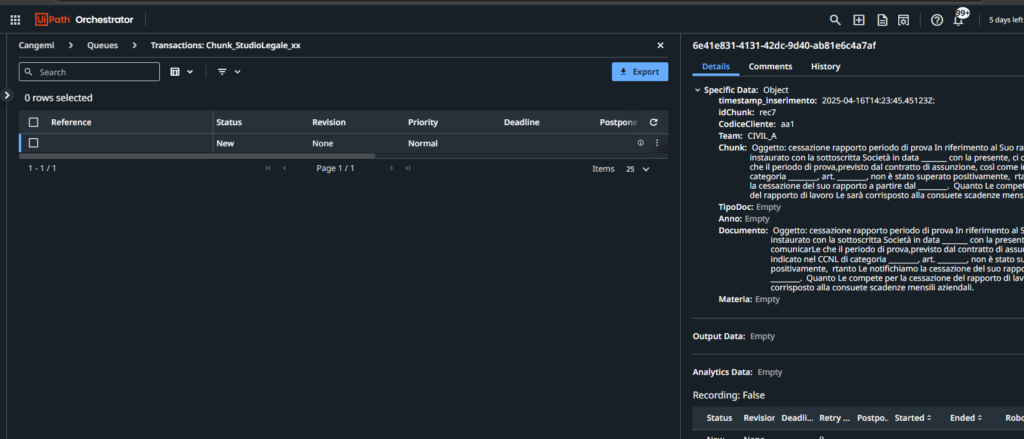

Quando l’avvocato carica un fascicolo sul portale, le prime due etichette – Cliente e Team legale – vengono assegnate manualmente; tutto il resto deve correre in automatico. Abbiamo già integrato il processo di chunking, così ogni file viene suddiviso in frammenti maneggevoli e indicizzati. Il passo successivo è chiedere al modello di memorizzare i metadati esistenti e, in un secondo passaggio, di dedurre le categorie mancanti: anno di riferimento, tipo di documento, eventuali clausole di procura, ecc.
Questa fase rientra nell’ombrello delle attività di document understanding: estraiamo informazioni strutturate da testi non strutturati, valutiamo la loro qualità e – quando il modello è incerto – facciamo scattare un controllo umano. Se il JSON restituito dal modello presenta campi vuoti o ambigui, l’elemento viene parcheggiato in una coda di revisione; una segretaria dedicata lo apre, corregge o conferma, quindi lo rimette in flusso.
Per spostare tutto il carico di lavoro dalla postazione locale dell’avvocato al server centrale adottiamo il classico pattern Dispatcher / Performer di UiPath. Il dispatcher registra gli eventi in una coda dati dell’orchestrator: ogni voce contiene l’identificativo del documento, i metadati iniziali e il testo spezzettato. Il performer, eseguito in ambiente server, consuma la coda, interroga l’LLM con il prompt descritto in questo articolo, valuta la risposta e, se tutto quadra, deposita il risultato nel database vettoriale a valle. Così separiamo acquisizione e calcolo, ottimizzando risorse e tracciabilità.
Questa pipeline ci garantisce tre vantaggi concreti:
1️⃣ Scalabilità – il server può macinare richieste senza bloccare il desktop dell’avvocato.
2️⃣ Auditabilità – ogni step è loggato in coda: sappiamo chi ha corretto cosa e quando.
3️⃣ Qualità dei dati – l’intervento umano mirato elimina le zone d’ombra che ancora sfuggono all’auto‑classificazione.
Con questo quadro operativo in mente, passiamo ora ai criteri per scrivere un prompt che sia davvero chiaro, univoco e “amico” delle nostre code di automazione.
4. Installiamo la nostra mini chatgpt sul pc server dello studio legale
Nel video di sinistra l’occupazione di memoria e i tempi di risposta di un modello LLM locale di 7 miliardi di paramentri nel mio pc.
In quello di destra i tempi di risposta e la memoria di un modello di 70 miliardi di parametri.
Si consideri che spendendo meno di mille euro per una scheda grafica capace di eseguire i calcoli richiesti, i tempi di esecuzione si riducono enormemente anche per il secondo modello LLM.
Quindi: Su Uipath orchestrator abbiamo le code dei documenti da classificare. Il nostro dispatcher le prenderà ad una ad una per classificare i medesimi documenti. Per compiere tale analisi, come accennato negli articoli precedenti, abbiamo scelto di installare in locale un modello LLM. Come già detto non useremo AI esterne per salvaguardare la privacy e la sicurezza del dato. In particolare, stiamo utilizzando Llama3.1:latest da 7 miliardi di parametri, ritenuto uno dei migliori per la classificazione e abbastanza leggero da poter essere eseguito su un comune computer, pur richiedendo una certa capacità di calcolo. Tuttavia, occorre tenere presente che, proseguendo con l’implementazione delle funzioni di memoria e di sessione (ereditate da LangChain), il carico computazionale sul nostro sistema aumenterà ulteriormente.
Per imparare a caricare il proprio motore LLM e i modelli freeware cliccate qui oppure cercate su youtube un qualsiasi tutorial .. Non è affatto difficile farlo.
5. prompt engineering per le tre classificazioni che dobbiamo compiere
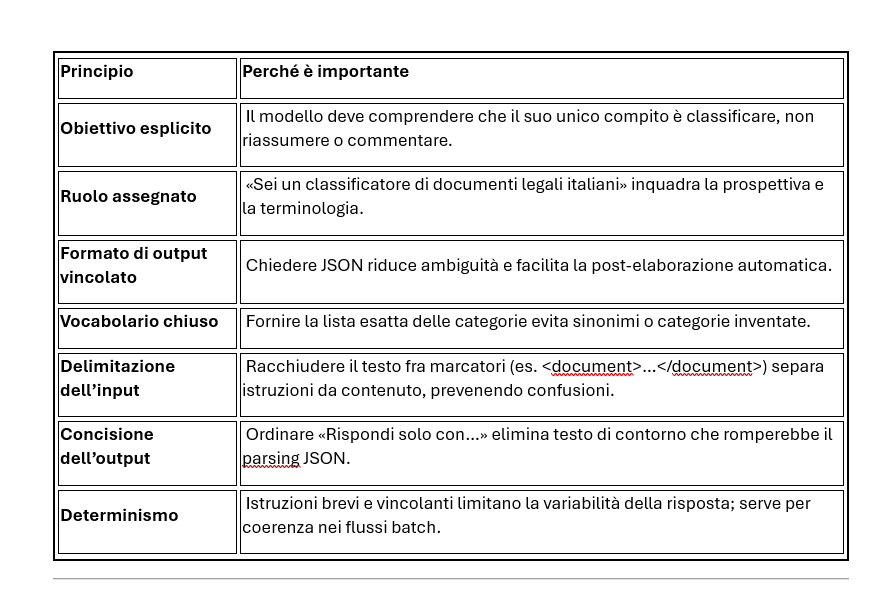
L’obiettivo è formulare un’unica domanda che induca il modello linguistico (LLM) a:
1. Leggere l’intero testo di un documento legale.
2. Stabilire con precisione a quale categoria appartiene, scegliendo solo tra quelle date
3. Stabilire con precisione a quale sottocategoria appartiene, scegliendo solo tra quelle date
4.Stabilire con precisione un grado di attendibilità dei risultati per attivare la funzione Human in the loop per i casi dubbi.
5. Restituire – senza preamboli né commenti – un oggetto JSON nel formato:
{"categoria": "<nome_categoria>":"sottocategoria":"<nome_sottocategoria>","accuratezza":"<grado di accuratezza>"}Di seguito i principi e le linee guida per costruire il prompt. seguendo esse ci saranno da fare delle prove e vediamo cosa ne viene fuori ..



Nel video testiamo i risultati del nostro sistema di classificazione confrontandoli con quelli forniti da chatgpt . Prove che hanno portato a ulteriori affinamenti e che ritengo soddisfacenti. La differenza con ChatGpt è che nel nostro modello i dati non hanno superato il perimetro dei nostri uffici. Con Chatgpt, invece, si.
Nel file sotto allegato i tre prompt utilizzati nel video per chi volesse approfondire.
Come valutare l’efficacia del prompt
- Accuratezza – % di documenti classificati correttamente su un campione etichettato.
- Tasso di conformità al JSON – quante risposte rispettano esattamente lo schema richiesto.
- Tempo di elaborazione – istruzioni concise solitamente riducono latenza.
Robustezza – prova con documenti fuori dominio o con formattazione irregolare; osserva se emerge la categoria «Non classificabile» prevista.
Cosa ho imparato ..
- Classificazione in batch
Ora la fase di classificazione avviene in batch perché i tempi di risposta del nostro LLM non sono immediati. In un contesto professionale questo cambio di strategia effettuato da quando ho iniziato a scrivere ad ora non sarebbe l’ideale. Qui stiamo sperimentando con strumenti nuovi: sbagliare fa parte del processo di apprendimento. Con il batch (dispatcher e performer) riusciamo comunque a garantire oltre 1.400 classificazioni al giorno, un volume più che sufficiente per il nostro studio. - Prompt come variabile globale
Il prompt va inserito in una variabile globale all’interno dell’orchestrator (asset). In questo modo si può modificare facilmente senza toccare il programma di classificazione. - Controllo di accuratezza
Bisogna aggiungere un controllo sui file di output per tutte le classificazioni che presentano un’accuratezza inferiore al 50%.
6. Facciamo una chiamata con node.js e Uipath alla nostra AI per classificare i documenti
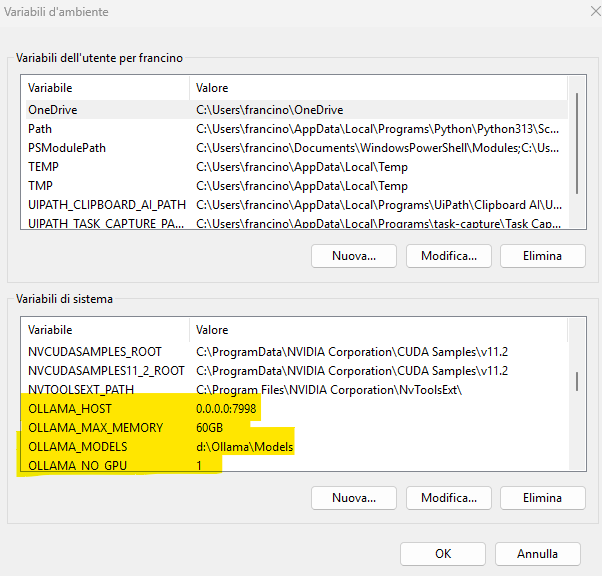
Abbiamo appena messo in piedi il nostro sistema di classificazione personalizzato. Abbiamo aggiunto quattro nuove variabili d’ambiente sul PC per farlo funzionare. L’unico dato che ci serve davvero ricordare è il numero di porta su cui “ascolta” il servizio: la 7998.
Adesso dobbiamo invocare il nostro LLm e passare il nostro prompt di richiesta e il testo del documento da analizzare tramite un processo automatico.
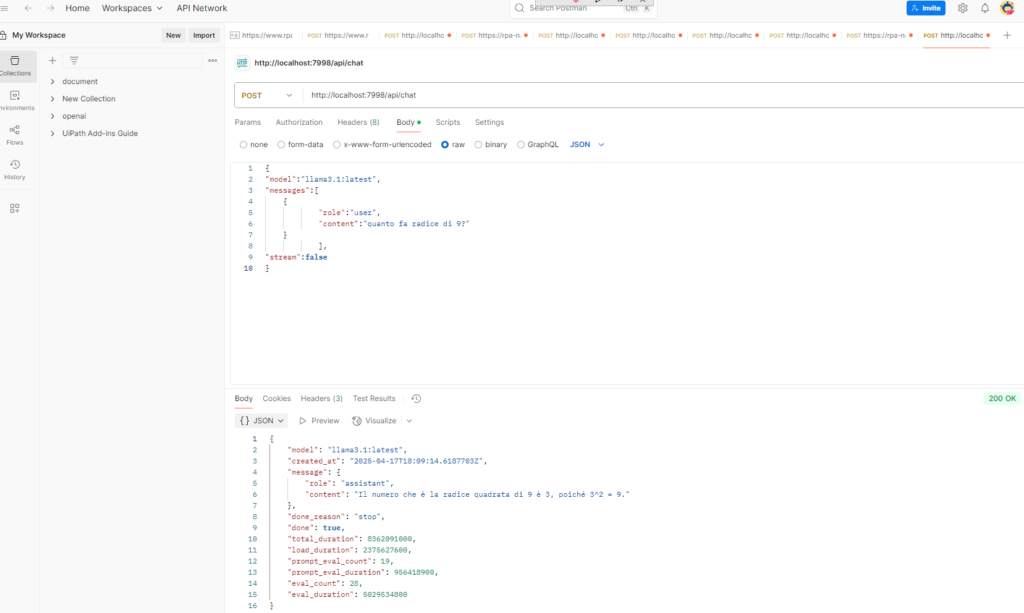
Per invocare il nostro modello privato possiamo scegliere fra due metodi. Il primo è il più immediato: fare una richiesta HTTP POST direttamente alla porta 7998 di Ollama con i dati da classificare e il prompt . È semplice da capire, ma diventa presto scomodo: dovremo scriverci da zero funzioni di supporto e importare librerie esterne (come LangChain e simili) ogni volta che vogliamo automatizzare il processo.
Secondo metodo : affidiamoci a Node.js e importiamolo nelle activities di Uipath

Ma non ne parliamo adesso. E’ già tanto se siete arrivati fin qui con noi . Ci siamo presi il tempo necessario e abbiamo ancora tantissime idee da condividere! Nel prossimo articolo entreremo nel vivo di Node.js e UiPath con esempi pratici, così potrete applicare subito quanto discusso fin qui. Scriverò davvero a breve, perché ho tutto pronto e poi mi prenderò una pausa per impegni professionali e di studio.
Ecco lo spoiler che vi farà venire voglia di tornare: presto vi mostrerò come far parlare la nostra chat su WhatsApp attingendo dai nostri datie e con la voce di personaggi famosi! Sarà un esperimento divertente e sorprendente.
Ci leggiamo prestissimo per la conclusione della serie e per completare insieme la fase finale di caricamento dei dati. Stay tuned!

