

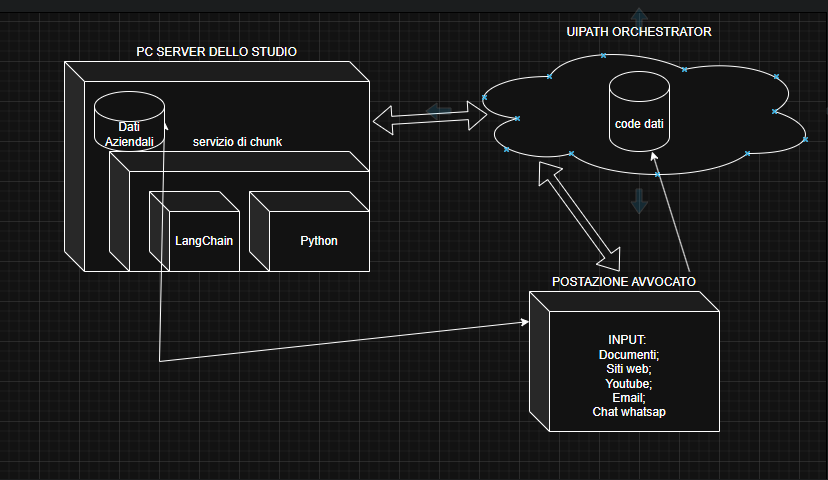
Primo step
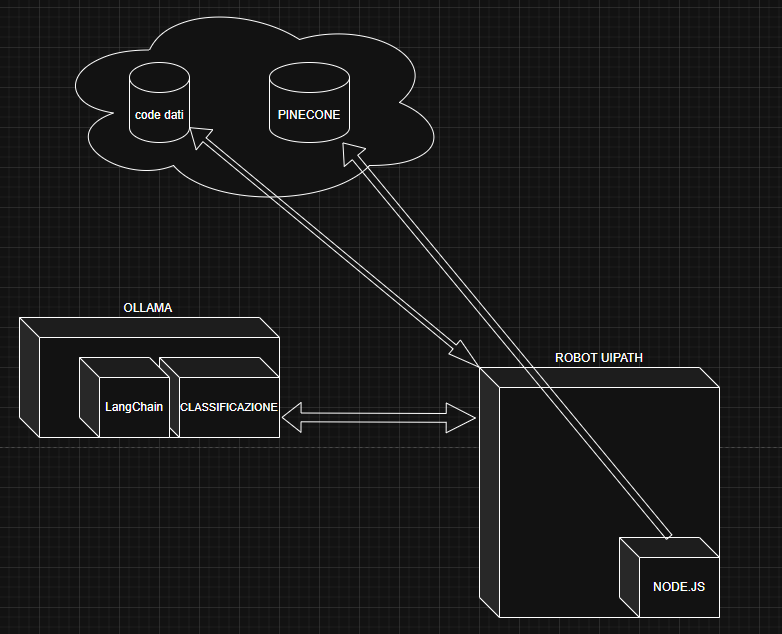
Secondo step
Ben tornati. Gli utensili sono pronti:
- Abbiamo una coda di dati su orchestrator con il testo da classificare e alcune classificazioni già date dagli avvocati che hanno caricato i documenti utilizzando tutte le fonti dati e i database aziendali;
- Abbiamo realizzato tre prompt per le tre classificazioni che ci occorrone e inseriti in una variablile globale (asset) su Uipath orchestrator
- Abbiamo installato sul server dello studio un server ollama e caricato il nostro modello llama3.1:latest
- Abbiamo scaricato le librerie langchain e pinecone;
- abbiamo inserito una attività umana nel loop per operare manualmente nei casi in cui il sistema non riesce a categorizzare i documenti
- Il nostro cliente ha visionato il processo e ha dettato l’elenco dei i test per verificare il funzionamento.
- I test sono andati bene e il sistema si comporta in modo solido.
La fase di caricamento dei dati è terminata !!
Adesso dobbiamo scegliere il linguaggio più adatto per automatizzare le chiamate al nostro modello LLAMA: il cuore del sistema sarà un robot UiPath che si attiverà non appena un documento semilavorato entra nella coda di processing, generata dalle attività di caricamento iniziale dei dati. Fino a questo momento, perr il caricamento dei vettori, avevamo utilizzato un processo UiPath diverso, dotato di interfaccia grafica per l’accesso ai sistemi aziendali, che a sua volta invocava in un container Docker una funzione di embedding.
Poiché l’attività che vogliamo implementare ora ha requisiti e funzionalità differenti: (qualunque utente per qualsiasi scopo da qualsiasi fonte => griglia autorizzazioni => attività o risposte )
è necessario ripensare le decisioni scegliendo il linguaggio e l’architettura più efficaci per gestire queste nuove esigenze.
Perchè Node.js?
Ci sono diversi fattori che possono portare a conclusioni differenti, ma io ritengo che Node.js sia la soluzione più adatta alla gestione delle chiamate con Ollama. Innanzitutto, è facile da isolare e funziona in modo indipendente dal contesto. Con un piccolo stratagemma puoi integrare gli script JavaScript direttamente in un progetto UiPath Studio e modificarli con un unico editor. Node.js è molto potente e splendidamente documentato: tutte le librerie di cui hai bisogno vengono importate e gestite direttamente dall’IDE.
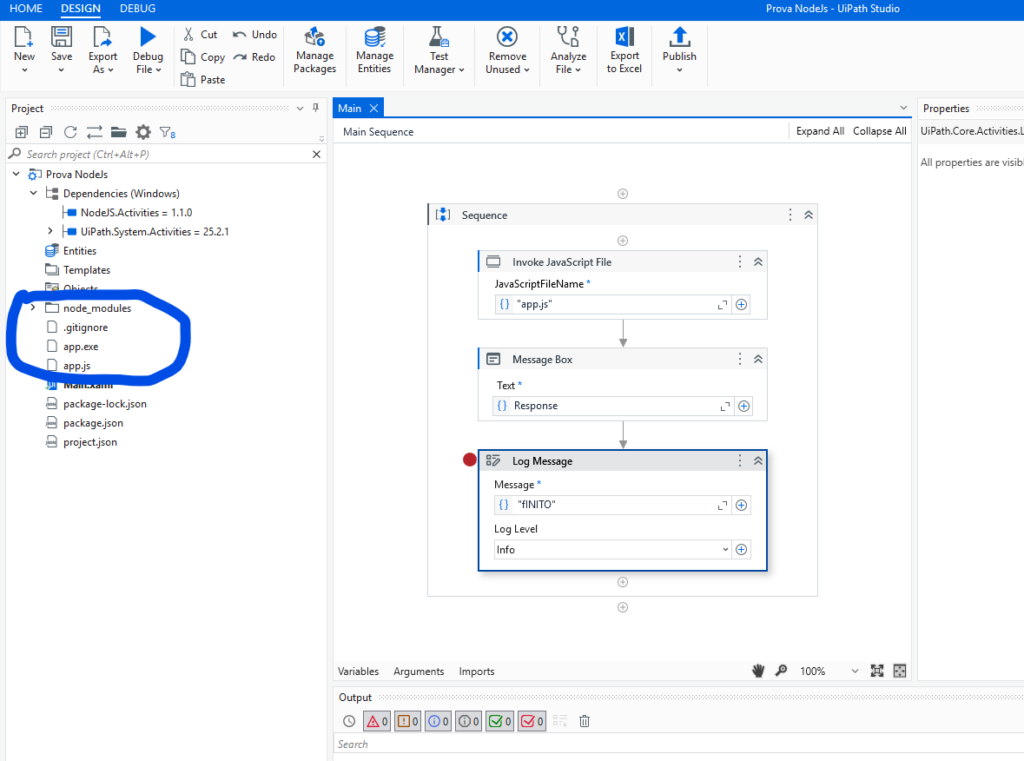
In allegato trovate un progetto UiPath che include una activity non ufficiale per eseguire direttamente script Node.js, senza installare eseguibili esterni. Basta inserire l’intero progetto Node.js nella struttura di cartelle di UiPath, così da garantire la corretta creazione dei pacchetti .nuget. L’esempio funziona subito dopo aver installato Ollama sul PC e configurato il modello LLM.
in esso trovate un esempio di scrittura della chiamata. Essa è diversa in termini di parametri a quella sviluppata per il nostro progetto ma può servire per avere una traccia per capire cosa c’è sotto il cofano.
Il prompt di istruzioni per il modello in questo caso è dentro lo script di node. In realtà nel nostro progetto tutto è inserito in variabili su orchestrator e code dati.
Bisogna anche scaricare le activity di uipath. per farlo cliccate qui. Spero che questa soluzione per integrare progetti Node.js in UiPath vi sia utile: fatemi sapere come va!
Per chi non ha voglia di scaricare . Inserisco un breve video in cui invochiamo i servizi di ollama per classificare un testo. vogliamo estrarre informazioni sul colore del vestito e sull’orario in cui si svolgono i fatti.
Perchè Uipath Orchestrator ?

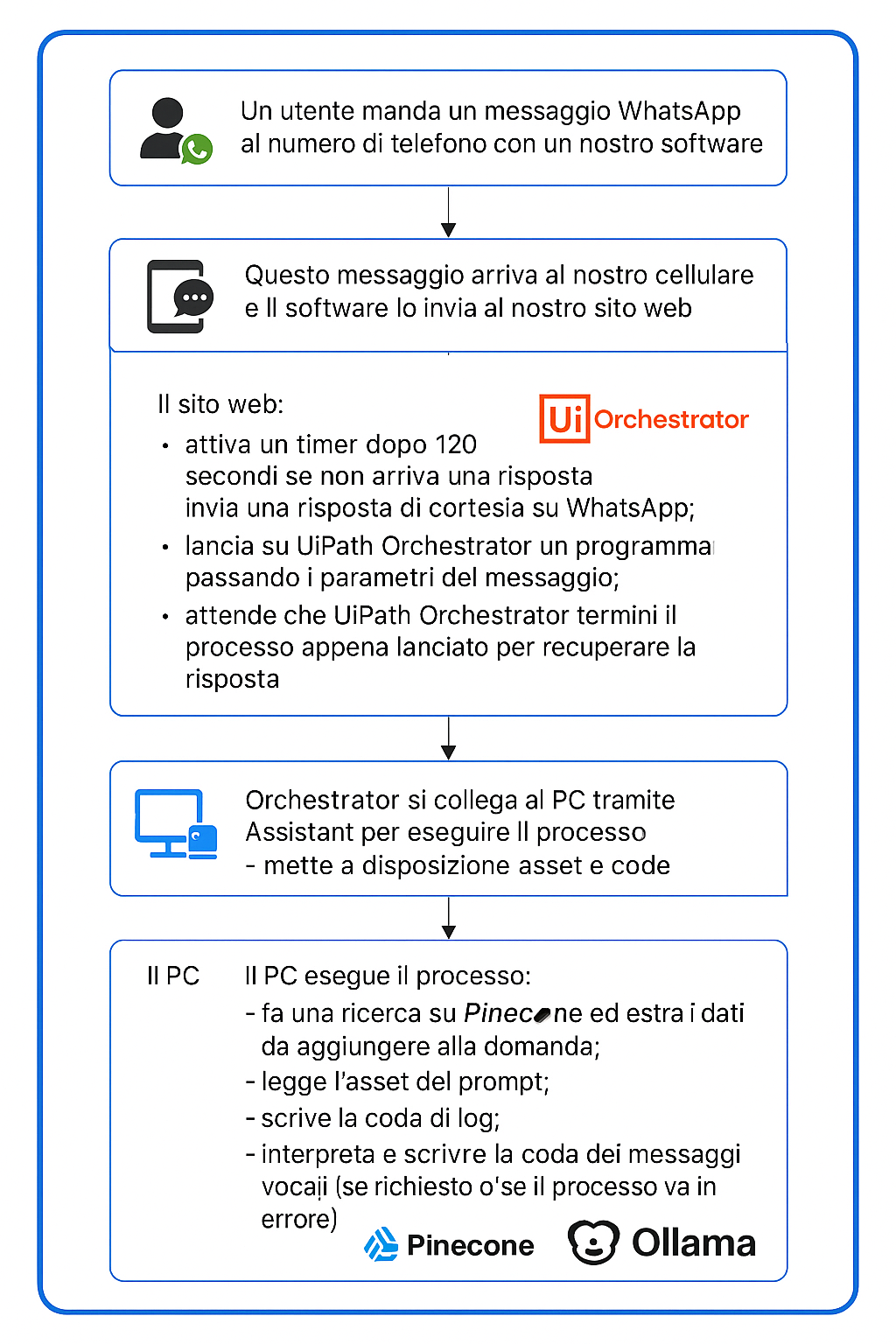
Immagina di inviare un semplice messaggio WhatsApp e, come per magia, si attiva una conversazione con questo nostro interlocutore AI che porta all’invio di un’email alla persona da te indicata e con i contenuti che hai scritto. Oppure pensa di poter avviare un processo aziendale, come il calcolo dei costi delle fatture emesse, con un semplice comando vocale. E che dire degli agenti che Uipath adesso mette a disposizione ?
Utilizziamo UiPath Orchestrator perché è il cuore dell’automazione dei processi aziendali. Grazie a Orchestrator, possiamo gestire in modo centralizzato e automatizzato tutte le attività: dal lancio di processi di business fino alla gestione delle code. Possiamo registrare e monitorare ogni attività, consentendo agli schedulatori di gestire operazioni in batch, come l’aggiornamento dei database o la gestione delle risposte vocali in modo asincrono. In altre parole, Orchestrator ci permette di avere un controllo completo e una grande flessibilità nell’automazione dei processi, rendendo le nostre operazioni più efficienti e affidabili.
1 connessione server web => orchestrator
Quando un utente invia un messaggio su WhatsApp, questo messaggio viene intercettato e interpretato come una richiesta diretta a un server PHP. Il mio server php con il mio endpoint di riferimento riceve la chiamata con i parametri (cellulare o nome utente, messaggio) , a sua volta, invia questi parametri di richiesta a UiPath Orchestrator attraverso:
–Un’autenticazione OAuth2;
– Una successiva richiesta di lancio del processo specifico.
Questa ultmia richiesta porta con se in response l’id univoco del run del processo e lo stato del processo (inizialmente in pending).
Questo processo è quello a cui sono agganciate le attività con il framework langchain , le attività di retrieve (RAG) dei dati sul database vettoriale di Pinecone.
Questo processo di UiPath gestisce anche l’esecuzione di altri processi suddividendo la richiesta attività da compiere. Una di queste attività è la generazione di una risposta alla domanda dell’utente, che può essere in formato testuale o vocale, a seconda delle necessità.
In questo modo, grazie all’integrazione tra UiPath Orchestrator e il modello linguistico personalizzato, è possibile automatizzare l’intero flusso: dalla ricezione del messaggio fino alla risposta generata dal modello o attività di business previste su orchestrator.

2 Classificazione di chi interroga
La classificazione degli utenti interni che interagiscono tramite WhatsApp si basa su tre elementi fondamentali:
Numero di cellulare dell’utente: questo numero rappresenta l’identificativo principale per ogni contatto. Quando l’utente non è già salvato nella rubrica del cellulare viene visualizzato solo il numero di telefono.
Nome nella rubrica: se l’utente è inserito nella rubrica del cellulare, abbiamo un collegamento diretto al database aziendale. In questo modo possiamo identificare se l’utente è un avvocato, un cliente o una persona autorizzata ad accedere a determinate informazioni.
Messaggio: il contenuto del messaggio viene elaborato e confrontato con le informazioni presenti nel database. Gli utenti interni, come gli avvocati o i clienti noti, hanno una corrispondenza diretta tra la loro richiesta e i dati classificati nel sistema.
Quando un avvocato contatta il sistema, possiamo risalire non solo alla sua identità, ma anche ai codici delle pratiche legali di cui è responsabile, così come alle informazioni sui clienti e sui procedimenti associati. Questo crea un collegamento bidirezionale tra chi pone la domanda e le informazioni a cui è autorizzato ad accedere o ai servizi che può richiedere (apertura di un ticket per la segretaria, inserimento appuntamento, interrogazione rubrica , invio email ..).
Se, invece, un utente contatta il sistema e il numero del suo cell chiamante non è presente nel database aziendale, viene classificato come “guest”. I guest possono visualizzare solo informazioni generali, come gli orari di apertura o le attività dell’ufficio, ma non possono accedere a dati riservati, poiché non dispongono della chiave che collega il loro profilo alle informazioni interne.
Questa classificazione segue e combacia con quella data per creare una dimensione delle classificazioni su pinecone . Questo garantisce la separazione delle informazioni “a prescindere dall’interrogazione veicolata dalla domanda espressa in whatsapp. Così strutturata, la classificazione garantisce un accesso sicuro e mirato alle informazioni aziendali, assicurando che solo gli utenti autorizzati possano accedere ai dati sensibili.
3 Prompt personalizzato
Nel capitolo precedente abbiamo visto come filtrare le informazioni aziendali in base a parametri specifici, garantendo che ogni utente acceda solo alle informazioni a cui è autorizzato. Un singolo utente, infatti, potrà visualizzare i propri dati solo se il numero di cellulare o l’indirizzo email da cui interagisce corrisponde esattamente a quello registrato nel database aziendale e quindi al codice di classificazione aggiunto in fase di caricamento del modello di linguaggio.
Oltre a questo meccanismo di filtraggio, la classificazione degli utenti permette anche la creazione di prompt personalizzati. Questo significa che, una volta identificato l’utente, il sistema può accedere a specifici asset all’interno di Orchestrator che descrivono esattamente il tono, le caratteristiche della comunicazione e il tipo di approccio da utilizzare con lui.
In pratica, per ogni utente classificato, è possibile definire un set di linee guida che il sistema seguirà per garantire una comunicazione coerente e personalizzata. Queste linee guida possono includere lo stile di linguaggio, il livello di formalità e tutte le specifiche già discusse durante la fase di progettazione dei prompt.
In questo modo, la comunicazione diventa non solo più efficiente, ma anche più mirata e in linea con le esigenze e le aspettative di ciascun utente. Ogni interazione viene così personalizzata, migliorando l’esperienza complessiva dell’utente e assicurando che ogni risposta sia appropriata e pertinente.
4 Dove è la risposta alla domanda ?

Una volta lanciato il processo su UiPath Orchestrator, la sfida è ottenere la risposta finale del processo. L’endpoint che usiamo per avviare il job restituisce solo lo stato iniziale e l’ID del processo, ma non il risultato finale. Il nostro server WhatsApp, nel frattempo, rimane in attesa della risposta definitiva da inviare all’utente.
Per risolvere questo problema, implementiamo un loop in PHP che effettua richieste a intervalli regolari (ad esempio, ogni 3 secondi). Questo loop utilizza il token e l’ID del processo lanciato per controllare lo stato del job. Quando il processo non è più “pending” o “running”, il loop verifica se è disponibile l’argomento di output con la risposta.
Se la risposta è disponibile, la inviamo subito all’utente. Se invece il processo è fallito o non contiene la risposta, informiamo l’utente che la risposta verrà fornita in un secondo momento. Questo approccio ci permette di gestire in modo robusto la risposta finale, anche se non arriva immediatamente, garantendo che il nostro server WhatsApp possa rispondere all’utente senza problemi.
5- Code per il lancio di messaggi vocali
Il lancio di messaggi vocali in UiPath Orchestrator avviene in modo asincrono, poiché dobbiamo trasformare le risposte testuali in file audio tramite un servizio esterno. Questa operazione richiede tempo, quindi non possiamo attendere il risultato finale in tempo reale. Invece, inviamo subito una risposta all’utente, informandolo che il messaggio vocale arriverà a breve.
Le richieste vengono inserite in una coda dedicata, dove un robot le prende in carico una alla volta per convertire il testo in audio e inviarlo. Questo processo asincrono è particolarmente utile, perché lo incapsuleremo come procedura di chatch all’interno del processo lanciato di generazione della risposta. Quindi metteremo un try per vedere Se qualcosa va storto nella generazione della risposta , il nostro sistema lo rileva e verifica se la risposta è stata generata. Se è stata generata la inserisce nella coda dei messaggi vocali mentre il server web, con la metodica del prossimo capitolo, fisiologicamente invia al nostro utente finale un messaggio del tipo .”per questa domanda ti rispondo dopo personalmente con un messaggio audio .. “.
Grazie a questo meccanismo, la generazione del messaggio vocale può avvenire in background, lasciando la conversazione sul web libera di procedere. I dettagli su come gestiamo la sessione web in attesa verranno approfonditi nel prossimo capitolo.

6- gestione del time out
Quando un messaggio viene inviato su WhatsApp, il nostro applicativo installato sul cellulare di riferimento intercetta la richiesta e trasmette i parametri (nome utente, numero di telefono, contenuto del messaggio) al server web. Alcune di queste chiamate avranno una risposta pronta, per cui la connessione HTTP rimane in stato di pending, in attesa della risposta del server. Tuttavia, anche questo tipo di attesa ha un limite: il sistema WhatsApp imposta un timeout di circa 125 secondi, superato il quale la richiesta viene considerata scaduta.
In casi in cui la risposta richieda un’elaborazione complessa, ad esempio per via dell’interrogazione di fonti esterne come Pinecone o per l’utilizzo di un solo robot disponibile (che potrebbe essere momentaneamente occupato da altri processi), il rischio è che la risposta arrivi troppo tardi. Se il job in UiPath Orchestrator parte con un ritardo e supera i 120 secondi dalla ricezione del messaggio originale, la risposta non potrà più essere recapitata entro il timeout.
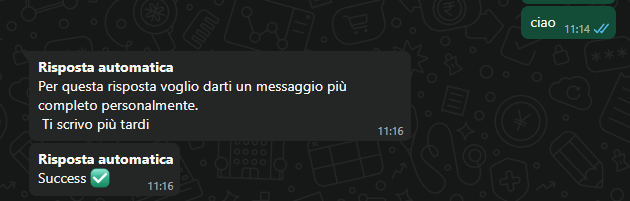
Per gestire questa eventualità, nel server web è stato implementato un meccanismo di controllo del tempo trascorso. Viene generato un parametro di timestamp iniziale se dopo aver inviato la richiesta ad orchestrator , il processo sul web arriva a una attesa di 110 risponde in automatico all’utente con un messaggio che spiega che la risposta arriverà in un secondo momento. Lo stesso comportamento si attiva anche in caso di errore del processo, garantendo così una gestione coerente delle eccezioni e dell’esperienza utente.
Altresì uipath ricevuto insieme al messaggio anche questo timestamp( $startTime), lo utilizza per valutare se l’elaborazione è ancora compatibile con i limiti di tempo. Se l’attività viene avviata troppo tardi, viene automaticamente instradata verso una coda asincrona. In questo modo, il sistema non tenta più di rispondere immediatamente, ma conclude il processo in background senza pressioni, e la notifica finale viene gestita separatamente.
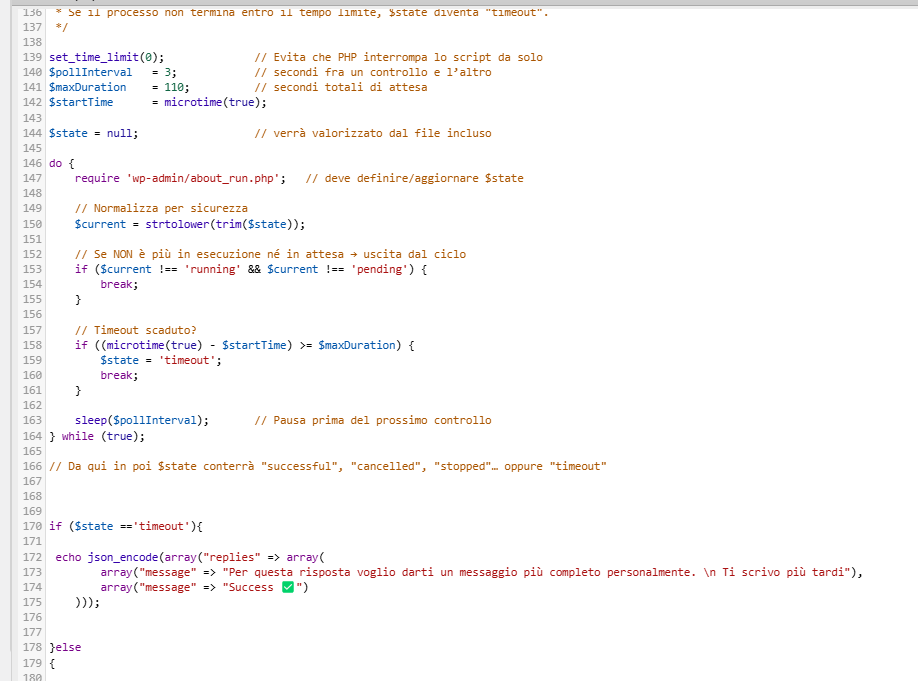
Abbiamo detto che lo stesso comportamento (scrittura dell’attività in una coda asincrona) viene prevista in caso di errore del processo. A questo punto è chiaro che non ci preoccuperemo della risposta perchè il server web arrivato in prossimità del timeout procederà ad inviare un messaggio di cortesia all’interlocutore in ogni caso ciò irrobustisce il processo in caso di errori.

Adesso che abbiamo tutto trascuriamo ciò che non abbiamo ancora fatto (la langchain in tecnologia RAG) e facciamo un video per provare tutto ciò che abbiamo.
Proverò a vincere la riservatezza e proverò anche a descrivere le fasi di funzionamento del processo.
Buona Visione! (il video è all’inizio di questo articolo).
Cosa rimane da fare ?
Dovremo ragionare anche come risolvere qualche problemino che la nostra fattispecie porta con se nell’utilizzo di RAG (recupero da Pinecone e Generazione tramite modello linguistico).
Dobbiamo creare la nostra langhchain creare contesti , decidere cosa trasferire di queste chiacchierate sul modello di linguaggio personale e provare il tutto.
n.B. ho qualche difficoltà a trovare informazioni e documenti utili al mio esperimento (studio di avvocati) .. penso di virare a un risponditore utile per il nostro network di professionisti che possa fare da assistente per tutti coloro che vorranno porre domande su questi articoli e su noi poveri apprendisti programmatori RPA che ne facciamo parte.

